Smart UI (Team ID: SU-208042)
Problem Statement
Generate a JSON file (output.json) from the screenshot of the wireframe. The file should contain the details of various elements used in the webpage.
Link to Detailed Problem Statement
Our Solution
Usage:
Clone the Repository:
> git clone https://github.com/tezansahu/smart_ui_tf20.git
> cd smart_ui_tf20/
Create & activate a virtual environment in Anaconda:
> conda create -n smartui python=3.7
> conda activate smartui
Note: The installation of dependenices & running of app works best in Anaconda with Python 3.7 &
tensorflow=2.3.1
Install the dependencies:
(smartui)> conda install -c conda-forge --file requirements.txt
(smartui)> pip install keras-ocr
Note: Since
keras-ocris not found in any of the Anaconda channels, it has to be installed separately as mentioned above.
Download necessary models & repositories for running the app:
(smartui)> python models/download_models.py # Download the models to be used by the app
(smartui)> git clone https://github.com/tesseract-ocr/tessdata.git ./app/tessdata/ # Clone the tessdata/ for legacy OCR being used in the app
Start the app:
(smartui)> cd app/
(smartui)> streamlit run app.py
This should start the app on localhost & fire up a tab in the browser
Overview:
We use a three stage pipeline to generate a JSON file containing the attributes of all the components in the input wireframe image. We then render the JSON output into an HTML file.
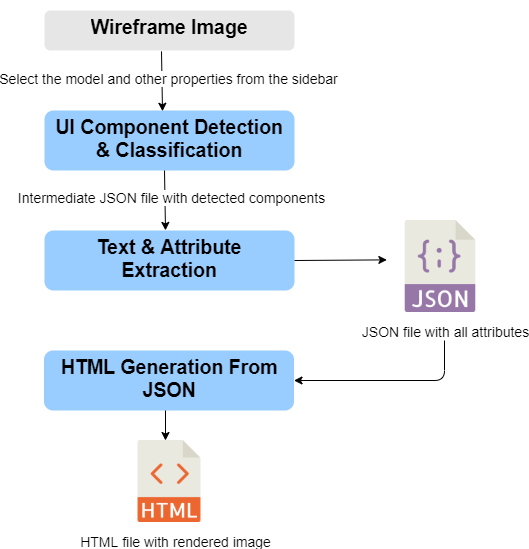
The pipeline, as shown in the figure, comprises of the following stages -
- UI Component Detection & Classification
- Text & Attribute Extraction for Identified Components
- HTML Generation from JSON
UI Component Detection & Classification
Taking inspiration from the paper “Object Detection for Graphical User Interface: Old Fashioned or Deep Learning or a Combination?”, we apply a hybrid approach (Traditional Image-Processing + Deep Learning) to identify the various UI Components from a Wireframe Image. The two stages of this process are described below.
Image-Processing Based UI Element Detection:
Given a wireframe image as input, we first segment out the regions containing probable UI components using Image Processing techniques including contour detection, etc. Details about the implementation can be found here.
Note: This portion of the code is an adapted version of the code found in UI Element Detection (UIED).
Deep Learning Models (for Classification):
The following DL Models (CNNs) have been developed to categorize the detected UI elements into specific classes:
- CNN Trained on RICO Dataset (Pretrained & used in UIED)
- CNN Trained on Wireframes Dataset (provided by organizers) (Transfer Learning using Model 1 as Base Model)
- CNN Trained on Generalized Dataset (Wireframes + ReDraw Dataset) (Transfer Learning using Model 2 as Base Model)
Details about the models, inculding their training, performance & downloadable weights can be found here.
Text & Attribute Extraction for Identified Components
For each of the identified components in the previous stage of the pipeline, its necessary attributes & styles are extracted, along with the text that the element may contain. These attributes include font & color related attributes. Details about the text recognition & attribute extracton process can be found here. The output is a JSON file containing the identified UI Elements along with their attributes (properties).
HTML Generation from JSON (Bonus)
The JSON file generated above is passed through the HTML generation pipeline to obtain a HTML file that renders the components identified from the wireframe image into a webpage. Details of this process can be found here.
Note: The HTML code generated may not be of the best quality, but can render the JSON with sufficient accuracy to relate it to the original image input.
Created with ❤️ by Rishabh Arya, Shreya Laddha & Tezan Sahu